Автоматизированная система оценки уровня загрузки трубной шаровой мельницы
Алгоритм начального заполнения базы данных представляет собой метод идентификации по шаблонам. Работа данного метода основана сопоставлении оцениваемого сигнала и калибровочного сигнала в базе данных, путем анализа количества битовых ошибок их ХЭШ-функций.
Конкуренцию данному методу составляет только методы с использованием алгоритмов искусственного интеллекта. Одним из таковых является предложенный метод идентификации на основе нечеткой логики.
При реализации данного метода необходимо задаться следующими лингвистическими переменными и их термами:
1) «ОШИБКА», которая может быть «БОЛЬШОЙ» и «МАЛОЙ»;
2) «ИДЕНТИЧНОСТЬ», которая может быть «ПОЛОЖИТЕЛЬНАЯ» и «ОТРИЦАТЕЛЬНАЯ».
На рисунках 2 и 3 изображены функции принадлежности этих переменных

Рис. 3. Функции принадлежности значений ошибки к термам переменной «ОШИБКА»
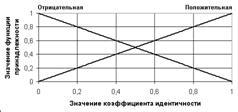
Рис. 2. Функции принадлежности значений коэффициента идентичности к термам переменной «ИДЕНТИЧНОСТЬ»
Из рисунков видно, что при идентичности сигналов коэффициент идентичности равен единице. Если акустические сигналы различны, то значение коэффициента равно нулю.
На следующем этапе определяются продукционные правила, связывающие лингвистические переменные. Совокупность таких правил описывает стратегию управления, применяемую в данной задаче. Для идентичности двух сравниваемых фрагментов необходимо, чтобы суммарные амплитуды сигналов в соответствующих диапазонах частот были равны (в идеальном случае) или были несущественно отличны друг от друга. На основе этого были построены следующие правила:
1) ЕСЛИ ОШИБКА1 = МАЛАЯ И ОШИБКА2 = МАЛАЯ И … И ОШИБКАN = МАЛАЯ ТО ИДЕНТИЧНОСТЬ = ПОЛОЖИТЕЛЬНАЯ
2) ЕСЛИ ОШИБКА1 = БОЛЬШАЯ ИЛИ ОШИБКА2 = БОЛЬШАЯ ИЛИ … ИЛИ ОШИБКАN = БОЛЬШАЯ ТО ИДЕНТИЧНОСТЬ = ОТРИЦАТЕЛЬНАЯ
Данный метод обладает лучшими временными показателями в сравнении с методом идентификации по шаблону.
Самонастройка системы основана на поиске 33-х информативных частотных диапазонов, используемых при генерации значений ХЭШ-функций. В основу алгоритма осуществляющего данный поиск положена структура генетических алгоритмов. При этом задача настройки сводится к поиску аргументов функции ![]() , представляющей собой сумму количества битовых ошибок для каждого из референсных фрагментов сравниваемого с калибровочными фрагментами в базе данных и соседних с ними (по условному уровню загрузки). Аргументами этой функции являются значения нижней частоты и ширины каждого из 33-х информативных диапазонов.
, представляющей собой сумму количества битовых ошибок для каждого из референсных фрагментов сравниваемого с калибровочными фрагментами в базе данных и соседних с ними (по условному уровню загрузки). Аргументами этой функции являются значения нижней частоты и ширины каждого из 33-х информативных диапазонов.
Таким образом обобщенная функциональная схема может быть представлена в следующем виде (рис. 4).

Рис. 4. Обобщенная функциональная схема системы оценки уровня загрузки трубной шаровой мельницы
Отображение текущего состояния уровня загрузки осуществляется в реальном масштабе времени с экспериментально подтвержденными интервалами замеров от 10 секунд.

Рис. 5. Интерфейс пользователя
Таким образом, разработанная система отвечает всем требованиям, наложенным на нее при постановке задачи. Позволяет оператору вести наблюдение за уровнем загрузки в реальном времени, а также при необходимости провести анализ возможных внештатных ситуаций путем проверки данных в текстовых файлах, представляющих собой отчеты системы.